- Published on
Understanding Context Windows in Large Language Models
- Authors
 MichałSoftware Developer
MichałSoftware Developer
Imagine this: you've received a shopping list with 10 items, but when you arrive at the store, you realize you left the list at home, and you can only remember the last five items. The rest are a blur. You try to recall what else was on the list, but all you can do is guess. It's not the most efficient way to shop, and you'll likely miss something important.
Now imagine you could remember all 100 items from a much longer list. Sounds better, right? But there's a catch. Recalling a specific item, like number 51, suddenly takes longer. You have to sift through more information, focus harder, and your brain needs more time to process everything.
Large Language Models (LLMs) work in a similar way. Their context window determines how much information they can "remember" at once, and how efficiently they can reason about it.
With that in mind, let's take a closer look at what a context window really is and how it affects your interactions with an LLM.
What Is a Context Window?
The context window defines the size of an LLM's "working memory." It represents how much text the model can process at once during a single request or conversation. This capacity is measured in tokens rather than characters or words. Roughly speaking, one word corresponds to about 1.5 tokens.
Different models support different maximum context sizes:
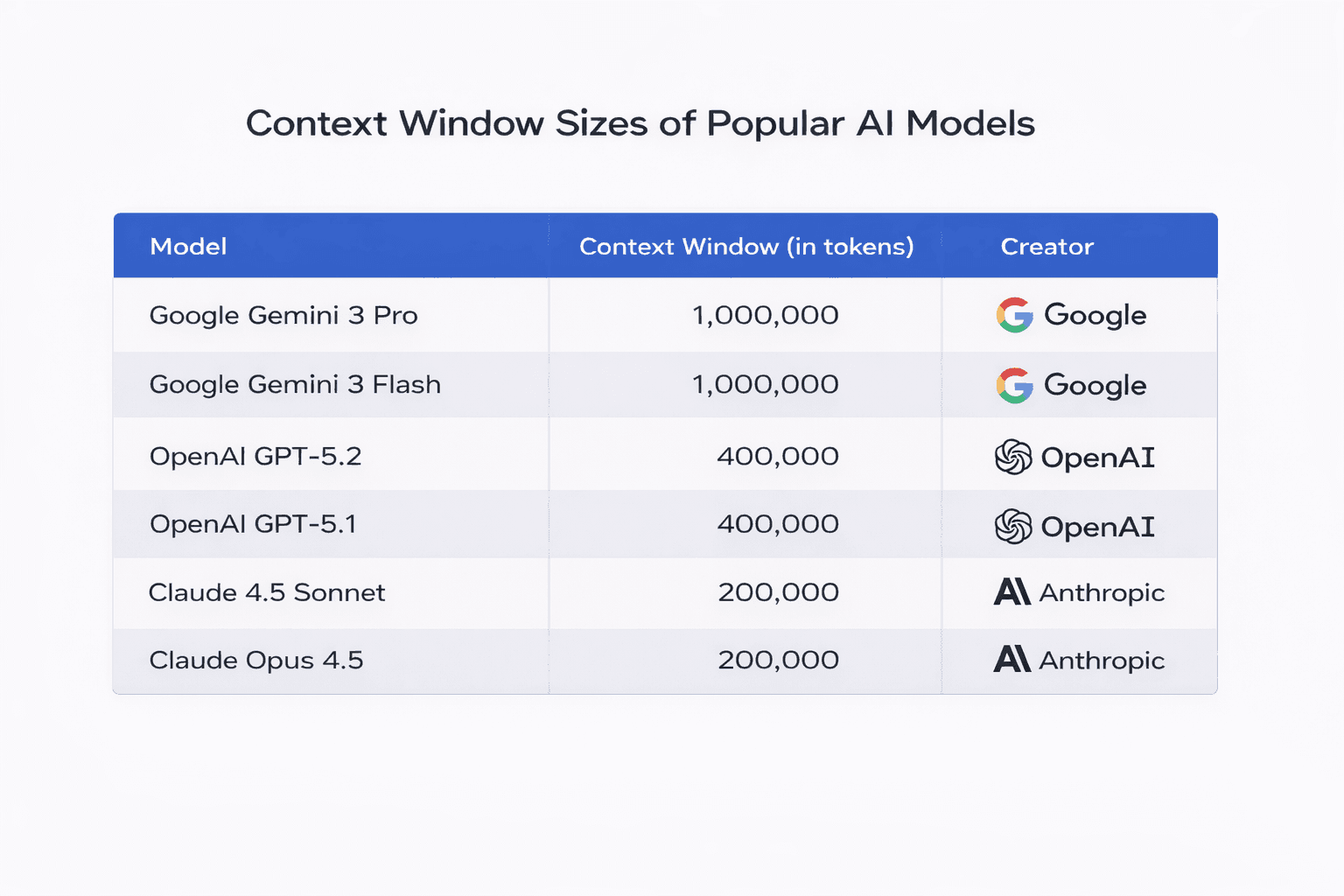
When using ChatGPT, each question you ask and each response you receive are stored in the context window. Every new message consumes part of the available token capacity, reducing the remaining space for future conversation.
What Happens When You Exceed the Context Window?
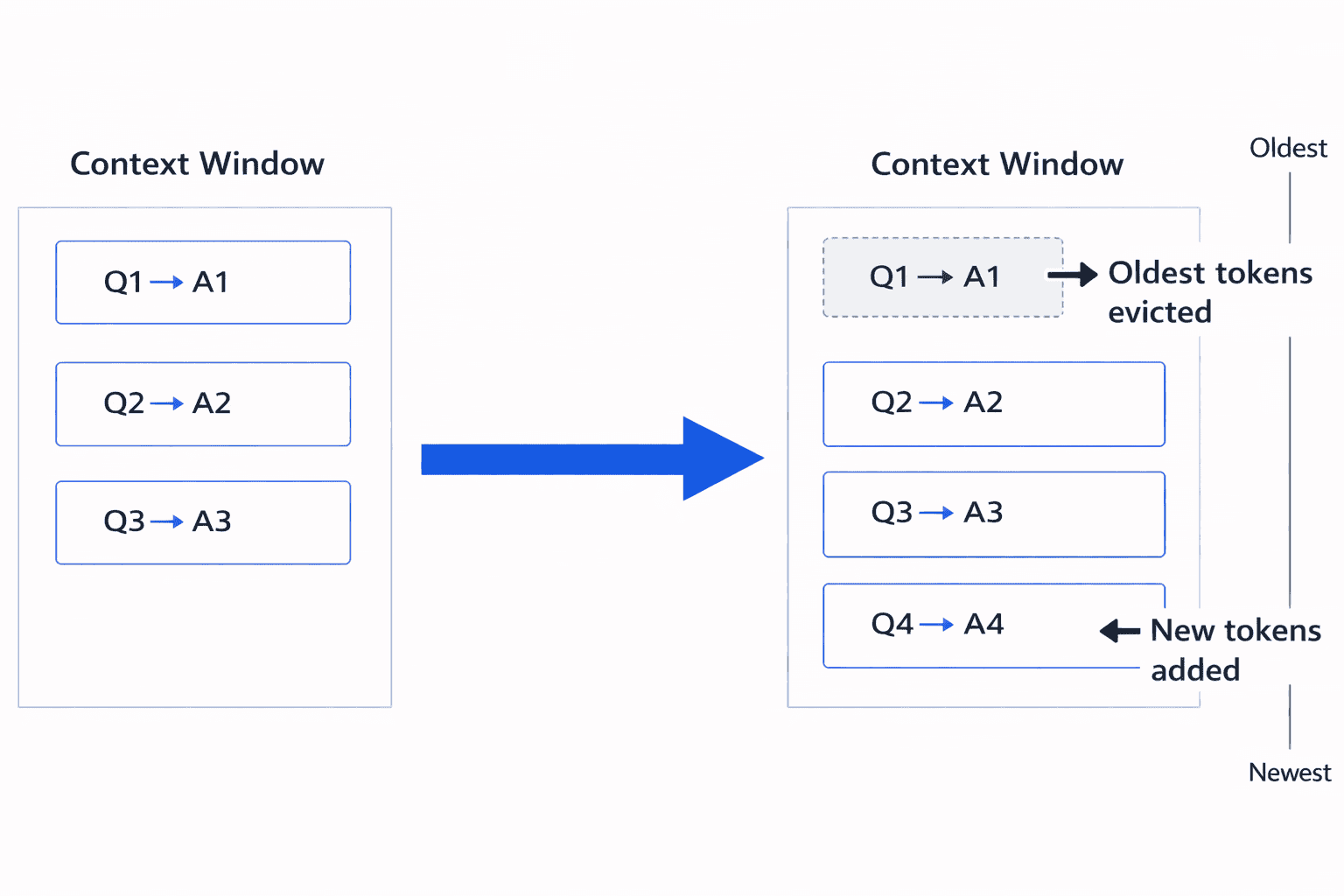
When the total number of tokens exceeds the model's maximum context size, the window is shifted. Older parts of the conversation are removed (evicted) to make room for new tokens.
This means the model literally no longer sees the earliest messages or data you previously provided.
If you later ask a question that depends on information that has already been evicted, the model has no access to that data anymore. It will attempt to infer or guess the answer based only on what remains in the current context. This often leads to incorrect answers or hallucinations, similar to trying to remember the first five items of your shopping list when they're already gone from your memory.
Does Size Matter?
A larger context window allows a model to process more information at once: longer documents, richer conversations, more examples, and more complex instructions. However, this comes with several trade-offs:
- Computational Cost - computation scales roughly quadratically with sequence length. As the context grows, memory usage, latency, and cost increase significantly. Processing very long prompts is therefore more expensive and slower.
- Performance and the "Lost in the Middle" problem - Interestingly, more context does not always mean better performance. Models often perform best when the most relevant information appears near the beginning or the end of the prompt. When important details are buried deep in the middle of a long input, the model may struggle to retrieve and prioritize them. This effect is commonly referred to as the "lost in the middle" problem.
Conclusion
The context window defines how much information an LLM can actively reason about at any given time, but more tokens do not automatically mean better results. Large context windows enable longer conversations, larger documents, and more advanced workflows, but they also introduce higher computational costs, increased latency, and cognitive effects such as the "lost in the middle" problem.
In practice, effective use of LLMs is less about maximizing context size and more about managing information intelligently.
Understanding how context windows behave allows you to design more reliable AI systems, reduce hallucinations caused by evicted context, and build applications that scale predictably, both technically and economically.